
来源:财经报道网
2026-03-29 18:53:48
(原标题:道通科技硬核突破:极简 0.5B 架构下的高性能机器人SimVLA)
技术深度解析
SimVLA:践行奥卡姆剃刀,以极简VLA架构重塑机器人操作基准
在通用机器人操作领域,视觉-语言-动作(Vision-Language-Action, VLA)模型作为具身智能的核心范式,近年来陷入了“复杂度军备竞赛”的发展误区。学界与工业界纷纷通过叠加3D几何先验、复杂时空注意力模块、多阶段解码结构,或是盲目扩容模型参数量,试图突破性能上限,却忽略了一个核心问题: 复杂架构带来的工程冗余,算力损耗巨大。OpenVLA的模型规模达到约7B参数,往往需要RTX4090或A100等高端GPU才能运行。
针对这一行业痛点,道通科技旗下Frontier Robotics团队潜心研发,正式推出SimVLA(Simple Vision-Language-Action)极简基准模型。该成果以“如无必要,勿增实体”的奥卡姆剃刀原则为核心设计哲学,严格剥离冗余架构设计,通过感知与控制深度解耦、核心训练流程全标准化,实现了仅0.5B参数量的极简模型,在多项标准基准测试中超越数十亿参数量的复杂SOTA模型,同时大幅降低算力门槛,为VLA领域搭建了透明、可复现、高性能的基准坐标系。相关研究论文已公开于(arXiv:2602.18224),项目代码、权重与全套部署方案已全面开源,助力具身智能技术落地。
核心技术定位:SimVLA并非单纯追求SOTA的新型模型,而是面向VLA领域的标准化基准框架,通过极简模块化设计与严谨训练范式,厘清性能增益核心要素,为后续架构创新提供公平对比标尺,同时兼顾工程落地的高效性与易用性。
领域痛点与研发初衷:告别冗余,回归VLA本质
当前VLA模型研发存在三大核心痛点,制约了技术从实验室走向实际场景:
基于此,SimVLA团队确立了清晰的研发目标:打造一个尽量简洁、模块解耦、训练流程标准化的 VLA 基线,在较低参数规模和算力开销下实现具有竞争力的机器人操作性能,并为后续方法提供更透明、更可复现的比较参照。

SimVLA 在真实机器人上的零样本部署表现
涵盖了收纳、插花等复杂任务
这种“做减法”的设计不仅让模型更透明,还带来了一个巨大的工程优势——极高的效率。如下表所示,SimVLA 在Batch=8时的峰值训练显存仅需9.3GB。相比之下,7B规模的 OpenVLA-OFT 需要62GB。这意味着,你甚至可以在一张普通的消费级显卡(如RTX 3090)上轻松训练和微调自己的机器人策略。
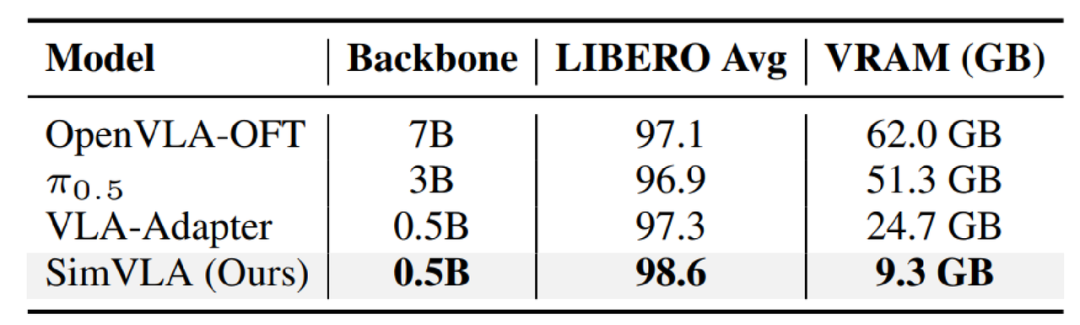
SimVLA 与主流模型的性能及效率对比
其显存占用优势巨大
核心架构设计:感知控制深度解耦,极简模块化极致优化
SimVLA摒弃复杂耦合设计,采用“VLM骨干编码器 + 轻量级动作头”的二元模块化架构,严格划分感知理解与动作执行两大功能模块,实现职责分离、高效协同,遵循尽量简洁的设计原则。
(1)整体工作流程
模型端到端推理流程清晰可控,全程无冗余计算,适配机器人实时控制需求:
• 多模态输入:接收多视图RGB图像、自然语言指令、机器本体感受状态(关节位置、姿态等)三类核心输入;
• 感知特征提取:VLM骨干编码器单次前向推理,完成视觉与语言特征融合,输出跨模态融合Token;
• 动作序列生成:轻量级动作头基于融合特征、本体状态与时间嵌入,通过流匹配去噪,输出连续动作块(Action Chunk),完成机器人控制指令生成。
• VLM骨干编码器:通用感知引擎
采用预训练视觉-语言模型作为专用感知模块,仅负责跨模态特征提取,不参与动作生成,实现感知能力与控制逻辑的解耦。默认选用SmolVLM-500M-Instruct(0.5B参数量),也可灵活适配Florence-2等主流VLM骨干,无需改动动作头结构,具备极强的扩展性。
该模块核心作用:将多视图视觉信息与自然语言指令映射至统一特征空间,输出高维度融合Token,为动作生成提供精准的环境语义与空间位置先验,且每个控制步仅需推理一次,大幅降低推理延迟。
• 轻量级动作头:专用控制模块
采用轻量化Transformer编码器结构,分为小、大两种可配置规格,参数量仅约300M,极致轻量化,具体架构参数如下:
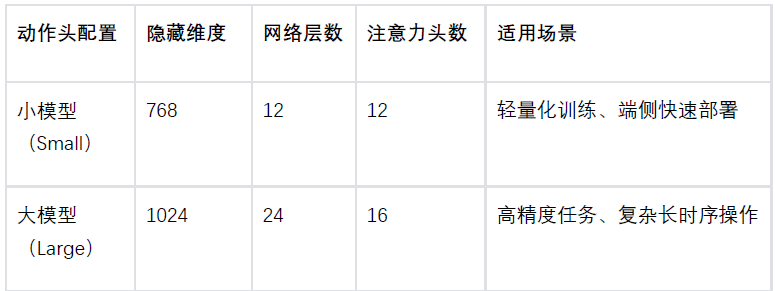
输入维度:融合VLM特征、机器本体感受状态、时间步正弦位置编码、加噪动作块四类信息,通过自注意力机制完成信息融合,全程无复杂交叉注意力、条件归一化等冗余设计。
• 动作生成机制:条件流匹配(CFM)连续动作建模
摒弃离散动作Token预测与不稳定的扩散模型,采用条件流匹配(Conditional Flow Matching, CFM)实现连续动作空间建模,这是SimVLA高效稳定的核心技术关键。
CFM核心原理:学习确定性向量场,将高斯噪声平滑转化为目标动作分布,训练目标为最小化L2损失,推理阶段通过少量欧拉积分步骤,即可从噪声中生成时序平滑、连续可控的动作块,相比扩散模型,推理速度更快、动作时序一致性更强、优化稳定性更高,更适合连续动作建模与长时序控制场景。
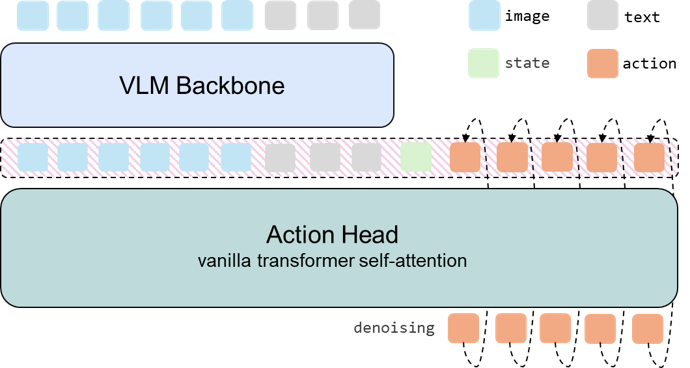 SimVLA 架构概览
SimVLA 架构概览
展示了从感知到动作生成的解耦流程
SimVLA 由两部分组成:
·VLM 骨干编码器(Backbone Encoder):负责“看”和“听”。它采用预训练的多模态大模型,将多视图图像和指令映射到一个共享的 Token 表示空间 。
·轻量级动作头(Action Head):负责“动”。这是一个纯粹的 Transformer 编码器,它接收来自 VLM 的特征、机器人状态以及时间步嵌入,通过自注意力机制融合信息。
这种解耦设计的巧妙之处在于:VLM 骨干网在每个控制步只需运行一次。后续生成动作时的迭代去噪过程全部在极其轻量的 Action Head 中完成。这大大降低了推理延迟,让机器人反应更敏捷。
标准化训练范式
SimVLA的核心突破不仅在于极简架构,更在于全流程标准化训练方案。团队通过大量消融实验验证,训练细节对VLA模型性能的影响,远大于架构微调,因此针对性标准化了四大核心环节,彻底解决复现性差、优化不稳定的行业难题。
(1)动作表示与归一化
基于训练集逐维度统计量,对连续动作空间与本体感受状态进行归一化处理,将数值范围缩放至稳定区间,大幅优化优化器收敛条件,避免因数值尺度差异导致的训练震荡。同时,针对不同基准任务,精细化调优动作块预测跨度H,适配长短期任务的时序需求。
SimVLA 遵循标准 VLA 范式:给定观测,预测未来连续动作块。
观测空间
ot=[It1,...,Itn, ℓt, st]
I:多视图 RGB 图像
ℓ:自然语言指令
st:本体感受状态(Proprioception)
输出连续动作块(Action Chunk):
At=[at, at+1, ..., at+H−1]∈RH×da
采用滚动时域执行(Receding-horizon control)。
(2)数据处理标准化
机器人演示轨迹具备极强的时序相关性,无序数据打乱会导致模型过拟合短时模式,长程泛化能力极差。SimVLA采用严格时序打乱策略,打破轨迹时序依赖,确保模型学习通用操作逻辑,而非记忆固定轨迹,这是模型鲁棒性的核心保障。
(3)优化动力学全管控
固定批次大小与总训练步数,系统性调优学习率、预热策略、学习率调度器,核心优化点:
• VLM骨干采用小学习率倍率(为动作头的0.1倍),保护预训练跨模态知识,避免微调过程中特征坍塌;
• 精细化筛选学习率取值,避免过高导致优化发散、过低导致收敛缓慢,确保优化过程稳定高效。
(4)架构配置标准化
默认采用极简动作头设计,消融实验仅调整动作头规模、VLM骨干类型、信息注入方式,所有变量可控,确保性能对比完全公平,为后续研究提供可复制的配置参考。
实验验证:小参数大能量,全面对标复杂SOTA模型
SimVLA在仿真基准、鲁棒性测试、真实机器人部署三大场景完成全方位严苛验证,全程无机器人预训练,仅靠极简架构与标准化训练,实现了性能与效率的双重突破。
(1)仿真基准测试:达到SOTA水平
在机器人操作领域权威LIBERO基准测试(包含Spatial、Object、Goal、Long四大任务套件)中,SimVLA全程无机器人预训练,仅0.5B参数量便实现顶尖性能,与主流大参数量VLA模型的详细成功率对比如下:
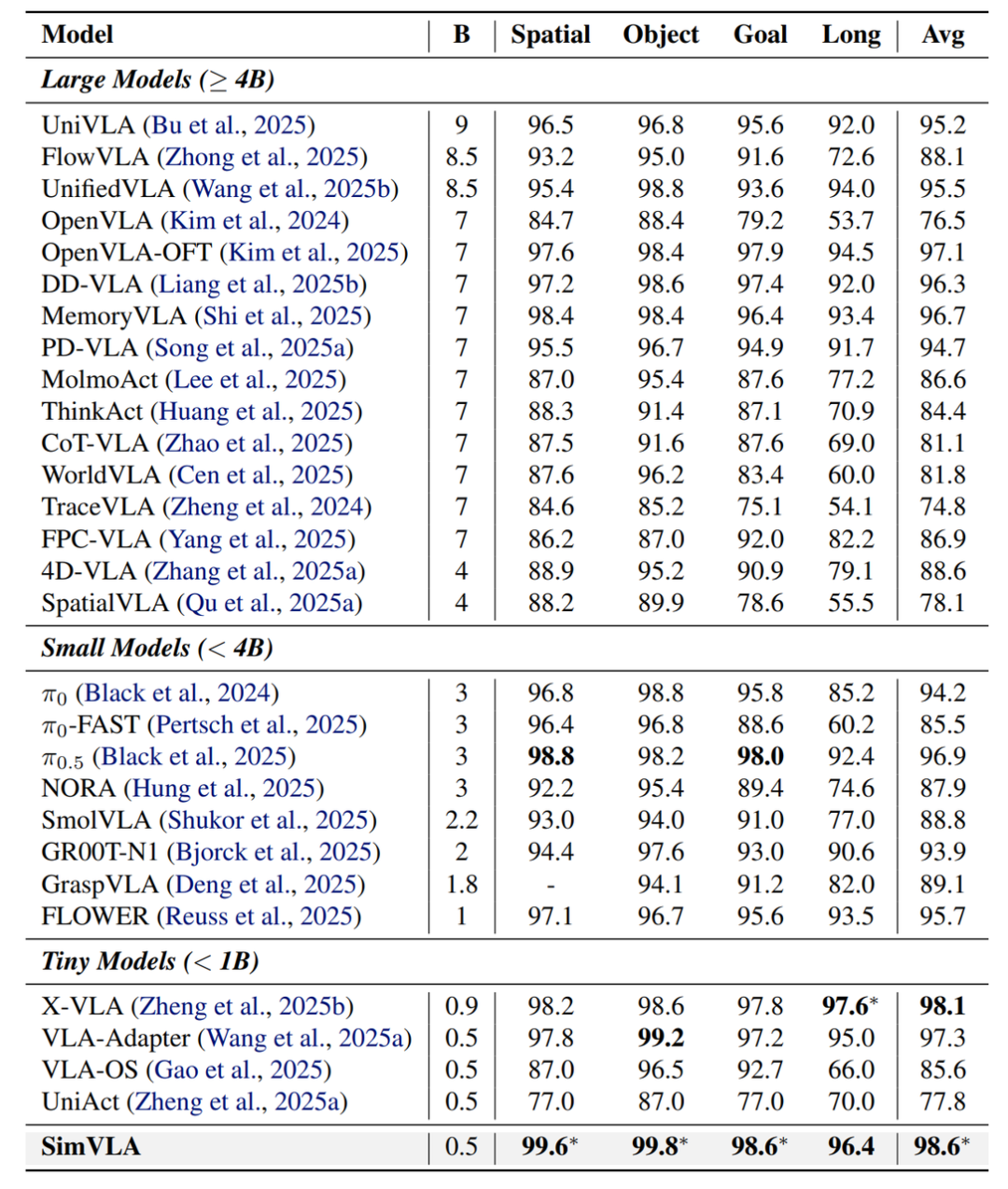
LIBERO 基准测试详细对比
SimVLA 在各子项上均表现优异
SimVLA 不仅在“Tiny Models”类别中遥遥领先,甚至压过了许多 7B、8B 甚至 9B 的巨型模型(如 OpenVLA、UniVLA 等)。在 LIBERO-Long 这种长程任务中,SimVLA 的表现依然稳健,证明了其流匹配机制在维持长时序一致性方面的优势。
(2)鲁棒性测试:LIBERO-PRO零样本泛化优异
在LIBERO-PRO鲁棒性基准中,针对物体外观、位置、语义描述、任务目标五大维度扰动,SimVLA保持了极高的任务成功率,尤其在语义、任务扰动下,性能显著优于同类模型,证明模型真正理解任务逻辑,而非单纯记忆轨迹。
SimVLA的轻量化设计带来颠覆性算力优势,训练显存占用远低于同类大模型,普通消费级显卡即可完成训练部署,具体算力参数对比如下:
极致的轻量化带来颠覆性算力优势:Batch=8训练时,峰值显存仅需9.3GB,远低于OpenVLA-OFT的62GB、π0.5的24.7GB,单张RTX 3090消费级显卡即可完成完整训练与微调,大幅降低VLA模型研发与部署的算力门槛。
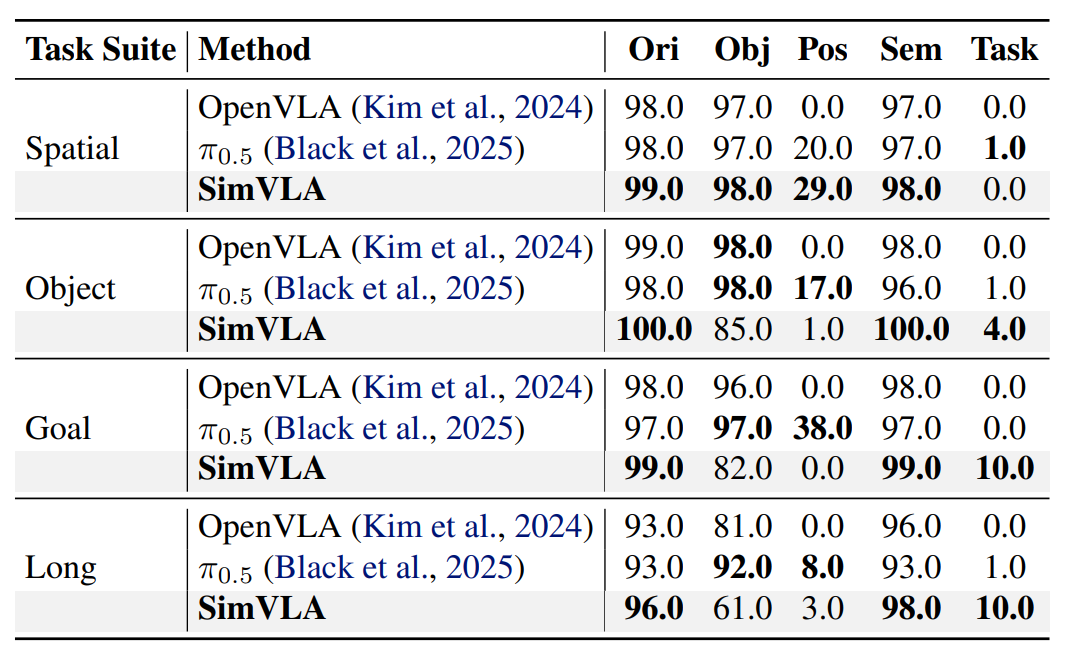
LIBERO-PRO 鲁棒性评估
展示了模型在不同扰动下的表现
WidowX 桌面精细操作基准:取勺子放置、胡萝卜收纳、杯子堆叠、茄子放置四大任务成功率均值为评估依据,SimVLA 原始场景成功率 95.8%,远超MemoryVLA(71.9%)和FPC-VLA(64.6%);物体外观、语义指令扰动维度将近满分,较π0.5(96.9%)提升1% 以上,OpenVLA则仅97%;空间布局、任务目标扰动维度,SimVLA保持对基线的绝对领先。
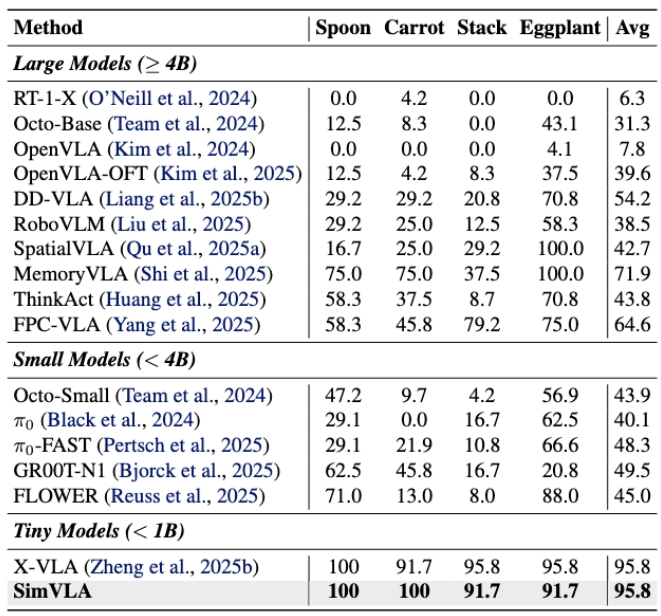
SimVLA与WidowX 机器人任务性能(成功率)对比
Google Robot 开放式家居操作基准:基于物体拾取、物体移动、抽屉开启三大任务均值评,SimVLA原始场景成功率77.0%,高于SpatialVLA(67.5%)和RT-2-X(65.6%);语义指令扰动维度98.0%以上,较π0.5(93.0%以上)提升5%以上;物体外观、空间布局、任务目标扰动维度,SimVLA(99.8%、99.4%、98.2%)均为三者最优; OpenVLA在空间、任务目标维度近乎失效,π0.5该两类维度成功率也不足20%。
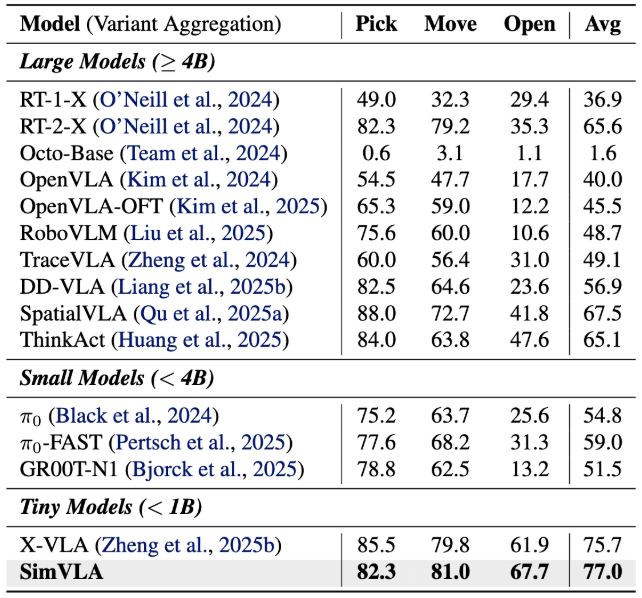
SimVLA与谷歌机器人任务性能(成功率)对比
(3)真实机器人部署:零样本跨场景迁移达标
在Galaxea R1 Lite双臂移动机器人上完成零样本部署,基于500小时开源数据集训练后,直接适配未见过的办公场景,完成收纳玩偶、插花、擦桌子、扔垃圾等8项多阶段复杂操作,整体成功率与3B参数量π0.5持平,部分任务(擦桌子、扔垃圾)成功率达100%,具备极强的实际落地价值。
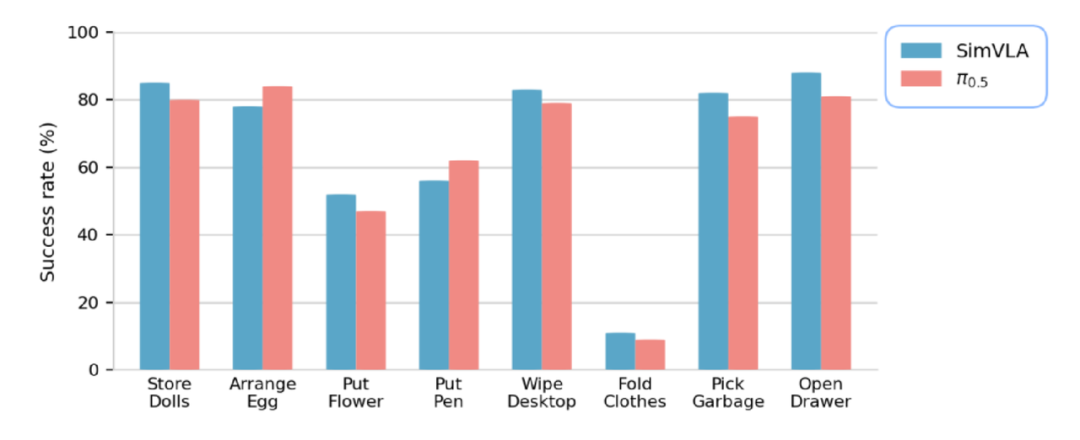
真机实验任务成功率对比
SimVLA 在多数任务上达到 80% 以上成功率
(4)核心消融实验结论:训练细节决定性能上限
团队通过控制变量法完成核心消融实验,固定其余参数仅修改单一变量,直观验证各训练细节、架构配置对模型性能的影响,实验结果如下:
从消融实验结果可明确:数据打乱、动作归一化、优化动力学配置是VLA模型性能的核心驱动力,影响程度远高于架构微调,极简架构搭配标准化训练,即可支撑顶尖性能。
通过控制变量消融实验,明确VLA模型性能核心影响因素:
• 关闭数据打乱:成功率从98.6%暴跌至9.9%,时序打乱是模型训练的核心前提;
• 关闭动作归一化:成功率降至12.3%,归一化是优化稳定的关键;
• VLM学习率倍率同步:成功率降至44.2%,小倍率保护预训练特征至关重要;
• 动作头缩容、替换信息注入方式:性能仅小幅下降,证明极简架构已足够支撑顶尖性能。
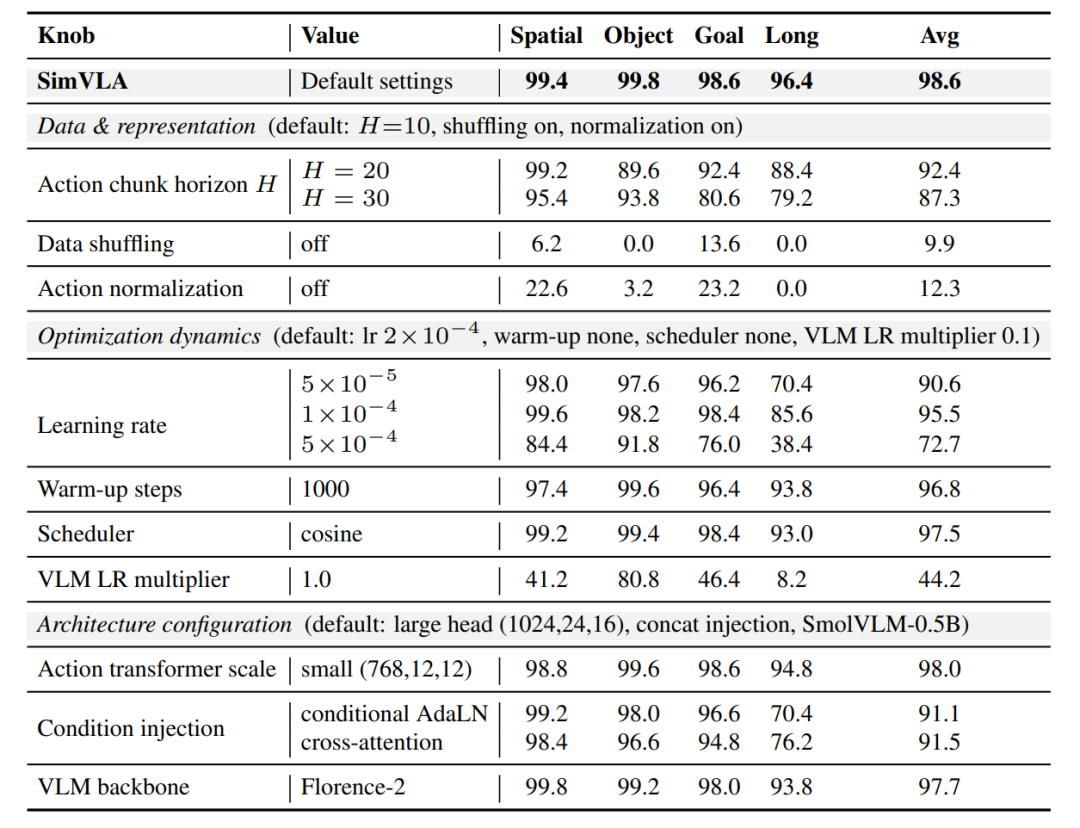
LIBERO 消融实验结果
展示了各因素对成功率的影响
领域价值与工程意义:重塑VLA研发范式
SimVLA作为Frontier Robotics团队的核心自研成果,不仅是一款高性能VLA模型,更对整个具身智能机器人领域具有深远的引领意义:
• 确立标准化基准:搭建透明、可复现的VLA基线,后续架构创新可直接对标,清晰量化创新价值,终结领域归因混乱的局面;
• 践行极简研发理念:证明奥卡姆剃刀原则在VLA领域的可行性,摒弃冗余复杂度,引导行业回归技术本质,聚焦真实创新;
• 降低技术门槛:轻量化设计+开源全栈方案,让中小团队、高校研究者无需高端算力,即可开展VLA模型研发与落地,推动技术普惠;
• 确立标准化基准:搭建透明、可复现的VLA基线,后续架构创新可直接对标,清晰量化创新价值,终结领域归因混乱的局面;
• 提升工程扩展性:感知控制解耦设计,支持灵活升级VLM骨干,适配多形态机器人,降低模型迭代与部署成本。
总结与展望
SimVLA以极简架构为骨架,以标准化训练为核心,打破了VLA领域“越复杂越强大”的固有认知,用0.5B参数量实现了SOTA级性能,完美诠释了奥卡姆剃刀的技术哲学。这一成果不仅为道通科技机器人具身智能技术积累了核心竞争力,更为整个行业提供了可复用、可扩展、可复现的研发范式。
未来,团队将基于SimVLA基准框架,持续优化轻量化动作头设计、拓展多机器人形态适配能力、优化端侧部署效率,同时推动极简VLA技术在工业、巡检、服务机器人场景的落地,助力具身智能技术从实验室走向规模化应用。
本文来源:财经报道网

财经报道网
2026-03-29
财经报道网
2026-03-29
财经报道网
2026-03-29
财经报道网
2026-03-29
财经报道网
2026-03-29
财经报道网
2026-03-28
证券之星资讯
2026-03-27
证券之星资讯
2026-03-27
证券之星资讯
2026-03-27



